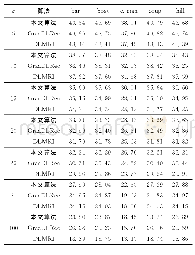
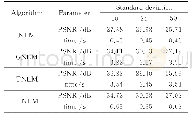
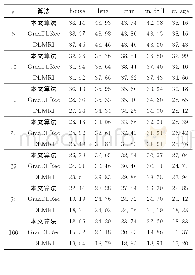
《表2 3种算法在不同图像和噪声标准差下的去噪后峰值信噪比数据比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由于GradDLRec和DLMRI算法采用了K-SVD字典学习方法,K-SVD字典学习方法需要事先设定或者采用交叉验证的方式确定正则化参数、字典规模、稀疏度等信息。考虑在实际应用过程中,这些参数难以进行设置和调整。根据非参数贝叶斯字典学习模型具有良好的推断能力,通过引入先验信息并结合贝叶斯框架,能够自动推断出正则化参数、字典规模和重建误差,有效地解决了参数选择问题。具体来说,K-SVD字典学习方法中有若干个参数需要设置,例如稀疏度(每个空间块向量使用的字典原子数)和字典规模;并且K-SVD字典学习方法还需要合理设置初始值,这些参数将影响图像重建的性能。同时,在有噪声的情况下,K-SVD方法必须知道噪声标准差,当存在数据缺失时,噪声标准差难以估计。一旦K-SVD字典学习方法未能设置适当的参数时,图像去噪性能会受到影响。本文使用BPFA字典学习方法的一个显著优点是在学习字典时,该方法可以对噪声标准差进行推断;另一方面,BPFA利用Beta-Bernoulli过程可以自适应更新稀疏模式。因此,在参数不确定的情况下,本文算法的去噪性能更优。
| 图表编号 | XD00137208600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.16 |
| 作者 | 朱路、刘松、曹赛男、刘媛媛 |
| 绘制单位 | 华东交通大学信息工程学院、华东交通大学信息工程学院、华东交通大学信息工程学院、华东交通大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
{kind=link}