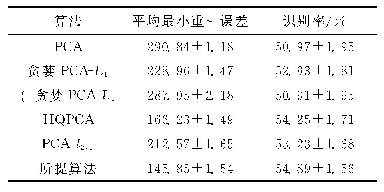
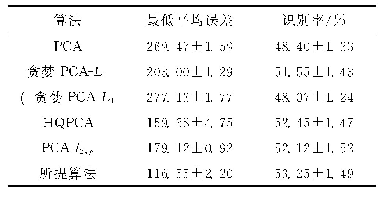
《表2 HELEN和300W数据集上人脸对齐模型平均误差比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
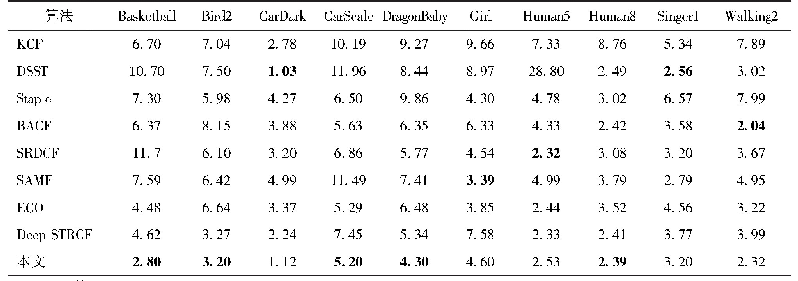
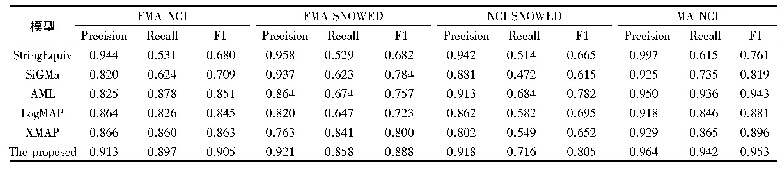
从表2可以看出,本文模型在两个数据集上的结果要好于其他模型。各种模型在HELEN数据集上的平均误差要高于300W common数据集,原因在于HELEN数据集有194个关键点,相对68个关键点,定位难度大。STASM平均误差最高,效果最差,特别是在300W challenge数据集上。因为该模型是基于ASM这种参数化的方法,该方法基于PCA线性模型,特征空间的表达能力受限,对于训练集没出现过的图片或者差异较大的图片不能表现出令人满意的结果。深度的方法MDM要优于ESR[6]、CFAN[17]等方法,在HELEN和300W common数据集上,平均误差低于本文模型,原因在于MDM增加了记忆机制,可以在相邻的级联回归迭代之间传递信息以及受益于深度网络较强的非线性映射能力。以上的方法都是将样本送入统一的框架,没有考虑姿态差异对模型训练带来的困难,本文模型考虑了姿态差异对人脸对齐的影响,将不同姿态的人脸送入不同的模型下进行训练,效果好于其他模型,尤其在300W challenge数据集上,准确度相比STASM提升47.3%,比MDM提升3.21%。
| 图表编号 | XD00134738000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 赵慧、景丽萍、于剑 |
| 绘制单位 | 北京交通大学计算机与信息技术学院、北京交通大学计算机与信息技术学院、交通数据分析与挖掘重点实验室(北京交通大学)、北京交通大学计算机与信息技术学院、交通数据分析与挖掘重点实验室(北京交通大学) |
| 更多格式 | 高清、无水印(增值服务) |
{kind=link}