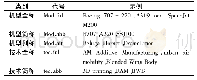
《表1 简历实体类别表:基于多神经网络协同训练的命名实体识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文在新浪财经随机选取1 024份上市公司的高管简历中文文本数据作为实验的语料,该语料包括了姓名、学历、籍贯、毕业院校等8种实体信息,8种实体描述见表1。数据集的规模为16 565条,实验过程中对语料随机选取20%作为测试集,20%作为有标记的训练集L,60%的数据集作为未标注集U。为了避免神经网络模型输入差异性对实验效果的影响,实验的过程中统一使用[-0.25,0.25]区间内随机初始化的方式得到的字向量作为3种初始化模型的输入。
| 图表编号 | XD00130383300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 王栋、李业刚、张晓 |
| 绘制单位 | 山东理工大学计算机科学与技术学院、山东理工大学计算机科学与技术学院、山东理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}