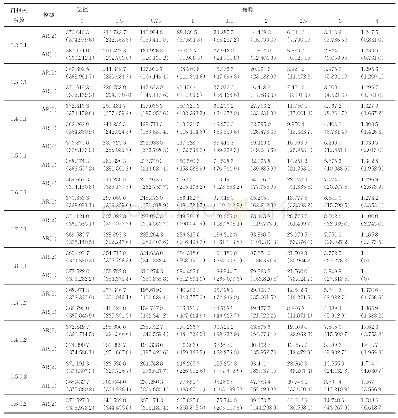
《表9 U-MIDAS(3,18)-AR(1)模型残差统计描述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
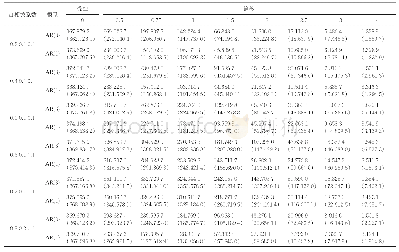
通过表9统计结果可以得出,无约束估计测模型残差的标准差低于MIDAS模型,说明前者模型残差较后者更加趋于平稳。同时,其残差的偏度为0.6225>0,此时残差序列正偏,向右拖尾。残差序列的峰度为1.9535<3,说明残差比较平缓。残差的雅克贝拉统计量P值为0.3617>0.05,表明该模型残差序列符合正态分布,这也进一步说明无约束模型对各指标数据具有良好的预测效果。本文又进一步对无约束估计模型进行三步向前预测,具体预测结果如表10所示。通过表10评价结果能够得到,当模型待估系数不受约束后,无论是一阶滞后模型还是指数型阿尔蒙混频数据模型,其均方根误差、平均绝对误差、平均绝对百分误差率等估计指标均出现了明显下降,模型对数据估计的准确性得到了提升,这反映出在估计我国国民生产总值时,非限制性混频数据模型相比于其他模型,更符合国民生产总值及网络消费者信心指数的数据特点,预测效果更为理想。
| 图表编号 | XD00106365700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.10 |
| 作者 | 李健、刘建民、李秋 |
| 绘制单位 | 石家庄邮电职业技术学院、河北师范大学、石家庄邮电职业技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}