《表1 不同数据集大小对预测模型的影响》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
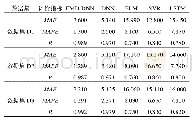
通过数据的预处理得到纯净的黑产用户数据之后。利用随机森林算法训练模型。初始的模型训练采用默认参数,得到在默认参数下的模型准确率。为了体现模型对数据集的依赖性,对不同的数据集大小下模型的准确率进行对比。训练结果如表1所示。
| 图表编号 | XD00103702100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.05 |
| 作者 | 章文俊、韩晓龙 |
| 绘制单位 | 上海海事大学物流科学与工程研究院、上海海事大学物流科学与工程研究院 |
| 更多格式 | 高清、无水印(增值服务) |
通过数据的预处理得到纯净的黑产用户数据之后。利用随机森林算法训练模型。初始的模型训练采用默认参数,得到在默认参数下的模型准确率。为了体现模型对数据集的依赖性,对不同的数据集大小下模型的准确率进行对比。训练结果如表1所示。
| 图表编号 | XD00103702100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.05 |
| 作者 | 章文俊、韩晓龙 |
| 绘制单位 | 上海海事大学物流科学与工程研究院、上海海事大学物流科学与工程研究院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}