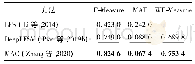
《表2 在FCD数据集上不同方法的图像裁剪精度对比结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
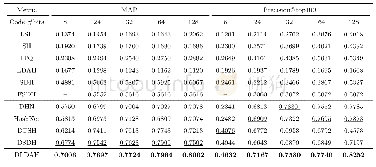
同时,对于数据集FCD,本文也将提出的模型与其他模型进行了对比。由于在该数据集上,每幅图像都只有一个相关的注释,故并没有具体列出注释的结果,同样为了对比实验的公平性,所有的模型都使用了相同大小的滑动窗口设置,对比结果如表2所示。从图4、表1和表2可以直观地看出对比结果,本文提出的A2-RL模型在图像裁剪精度方面优于其他模型,无论是在Avg IoU指标还是Avg Disp指标方面相较于其他模型都有了一定程度的优化和改进,从图4中第四行可以明显观察到VFN+SW方法的裁剪结果具有较多的无关信息,在保留前景目标信息的同时也引入过多的背景信息,这是因为VFN+SW方法依赖的滑动窗口机制需要固定的纵横比来限制以任意尺寸来进行图像裁剪处理,所提取到目标信息的精确度较本文算法仍然较低。而本文所提出的算法采用强化学习的奖励函数来对输入图像进行有针对性裁剪操作,更加有针对性地获得目标图像。智能体按照当前观察值和历史经验采取相应动作,执行该动作去调整裁剪窗口的形状和位置,积累每次动作获得的奖励并将其最大化,以此作为最佳裁剪窗口的确定依据。从而就可以在极其有限的候选项下依次搜索并得到高精度的裁剪图像。
| 图表编号 | XD00102833300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 张碧陶、庞振全 |
| 绘制单位 | 江西理工大学电气工程与自动化学院、广州市香港科大霍英东研究院、江西理工大学电气工程与自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}