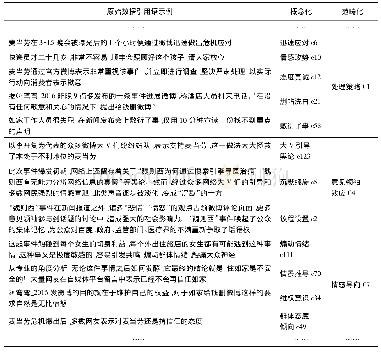
《表5 少数族裔健康差异研究中一个Excel编码文件示例*》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:*表示列出的名字是假名
为了开始或开启编码步骤,研究人员通过转录(和通过参与者观察、文件分析等收集的数据)进行了2次阅读并开始开启编码步骤。在此步,研究人员将“描述符”或“代码”分配给文本段或段落。代码通常是研究人员生成的结构,其为数据段赋予意义并为类别建构奠定了基础[8,27]。一些研究人员推荐逐行编码技术,即为每行所写数据标记或分配代码[28]。扎根理论家提倡使用充当名词的动名词或动词(以“ing”结尾)来表示行动和过程,因为定性研究经常涉及随时间推移的过程研究。合适时可分配鲜活代码。鲜活代码是从参与者获取的一字不差的短语,为了捕获一行或一文本段的意思。编码过程是递归的。研究人员将会重复进行这一步,每次均会重新阅读段落并重新编写代码。编码过程使得研究人员更了解数据并有助于形成促进代码微调的新见解。在此过程中,研究人员不断完善最终会成为类别的内容。在少数族裔健康差异研究中,研究人员为每个访谈问题开发了一个Excel矩阵并为每个受访者的回答开发了代码。利用这个矩阵可以让作者及其他研究人员看到每个问题的回答和代码,帮助作者及其他研究人员从数据中识别出数据中的模式和类别。表5显示了作者及其他研究人员如何组织其半结构化访谈协议中问题10的3个回答的分析和进行的多轮协作编码过程的两轮分析。
| 图表编号 | XD0092647500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.15 |
| 作者 | Wayne A Babchuk、马兰、汪洋、韩建军、许岩丽、杨辉 |
| 绘制单位 | University of Nebraska-Lincoln、University of Nebraska-Lincoln、中国全科医学杂志社、中国全科医学杂志社、中国全科医学杂志社、中国全科医学杂志社、Monash University |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}