《表2 25万训练集中文章长度分布统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
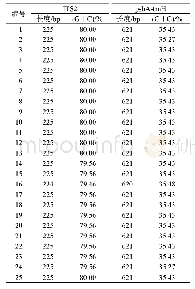
本文词向量采用Word2Vec进行预训练,维度d=300。对于未登录词,采用零向量表示。根据表2统计,文章中几乎99.8%的数据长度都未超度500,同时为了考虑数据输入的稀疏度问题,最终将文章长度m设置成500。通过统计,问题长度小于30的有249 999,因此问题长度n设置为30。Bi-GRU隐含层的维度设置为150。训练过程中,模型采用Adamax[21]作为优化器,学习率设置为0.1。误差采用批处理,batch-size设置为30。为避免过拟合,dropout设置为0.2。推理层数设置为4。共训练10轮(epoch),每一轮之后在验证集上测试性能,最终选择在验证集上效果最好的作为模型。
| 图表编号 | XD0091826100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 段利国、高建颖、李爱萍 |
| 绘制单位 | 太原理工大学信息与计算机学院、太原理工大学信息与计算机学院、太原理工大学信息与计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}