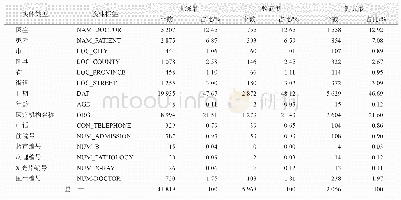
《表3 训练集和测试集中PHI实体分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验采用Informatics for Integrating Biology and the Bedside(I2B2)2006年、2014年英文评测数据集和某医院妇产科中文医疗文本.I2B2是美国国立卫生研究院资助的国家生物医学中心,2006年评测数据中隐私实体通过XML标签来标记,共包含年龄、日期、医生姓名、医院名、证件号码、地址、患者姓名、电话共8种命名实体.2014年数据集格式较2006年有较大变化,通过命名实体在整个文本中的偏移量来标记,其中的隐私实体类别也比2006年更复杂,共有7个大类,分别是姓名、职业、地址、年龄、日期、联系方式和证件号码,大类下又更进一步划分为多个小类.妇产科医疗文本来自某医院真实数据,包括入院诊断、住院经过、出院诊断等,标注格式与2006年I2B2格式一致.中文数据首先进行分词处理,其他处理步骤与英文语料一致.实验语料中隐私实体数量见表3.
| 图表编号 | XD0045010200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 李慧林、柴玉梅、孙穆祯 |
| 绘制单位 | 郑州大学信息工程学院、郑州大学信息工程学院、华中科技大学公共管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}