《表4 最优模型性能结果(实验结果省略%,F1值为宏平均)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
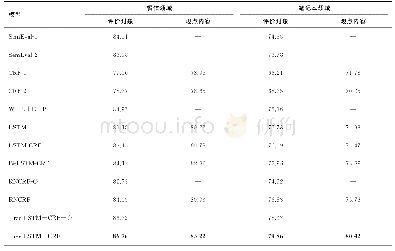
综合以上两组实验结果,本文在基线系统的基础上,组合利用自注意力机制的聚合策略和基于BiLSTM的整体建模思路,在关系抽取语料集上进行实验,并详细比较了基线系统和本文的模型在各个类别下的指标,实验结果如表4所示。从表中可以看出,相比基线系统的多通道CNN,本文的模型在各个类别均有性能优势。其中,召回率提升明显,说明原先被误判为other类别的样本都能被本文的模型正确识别。并且,观测发现,本文的模型在长句预测上的性能要显著优于基线系统。如例2中关系实例,基线系统判定为other类别,而本文的模型则正确标识为Member-Collection类。
| 图表编号 | XD0091825000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 宋睿、陈鑫、洪宇、张民 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |
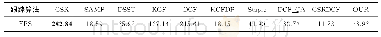
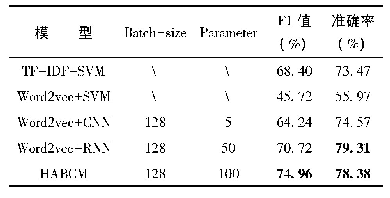



{kind=link}