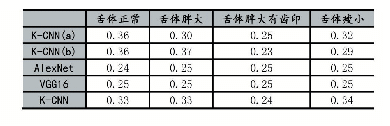
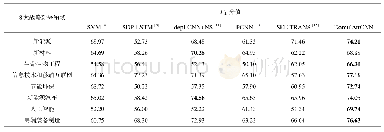
《表6 各模型最优调参下的F1分数比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《中文比较关系的识别:基于注意力机制的深度学习模型》
经过最优调参后,获得表6的各模型最优调参下的F1分数。结果显示,本文提出的层次多注意力模型在两个数据集中均取得了最佳性能,且隐性比较评论在一定程度上降低了模型的分类能力,含有隐性评论的深度学习模型表现均不同程度地低于不含隐性评论的模型识别效果。结果分为三类:线性模型,CNN和RNN,以及注意力网络。其中,注意力网络大幅提升了传统方法,较基于N-Gram和TF-IDF的传统分类器提升了14.24%和16.41%,表明词向量的文本表示方法与深度网络的结合,在中文比较关系文本分类任务中表现最为优异。同时,注意到不涉及层次文档结构的神经网络模型(如双向GRU和基于词的多通道CNN)也优于传统的线性模型分类结果,但其结果相对于采用注意力网络算法较差。HMAN算法与TextCNN算法相比,优势比较明显;而对于HAMN中的子模型双向GRU而言,HMAN算法略有优势,包含隐形信息的比较评论的F1和微平均F1仅分别提高了1.15%和1.75%。
| 图表编号 | XD0072253200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.24 |
| 作者 | 朱茂然、王奕磊、高松、王洪伟、郑丽娟 |
| 绘制单位 | 同济大学经济与管理学院、同济大学经济与管理学院、中国信息安全测评中心、同济大学经济与管理学院、聊城大学商学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}