《表5 特征向量对比:面向机器学习的流式文档逻辑结构标注方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
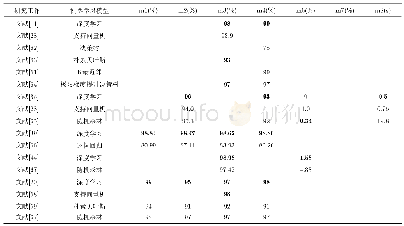
文献[1]对文档章节结构进行了识别,其数据集中标注了章节、子章节与正文,并提取8种编辑特征组成特征向量。为与文献[1]进行对比,随机选取169篇文档语料,首先按照文献[1]的方法构造数据集1;其次按照本文提出的方法标注相应标签并自动提取16种编辑特征,从中计算并选取信息增益[21]最大的8种特征组成特征向量,构造数据集2。两种数据集的特征向量对比如表5所示。基于上述两种数据集,构建随机森林分类模型,十倍交叉验证的实验结果见表6。实验结果表明,由于本文标注体系中对文档编辑特征提取得较为全面,能够更好地反映不同类别间的差异,从而提升了随机森林分类模型的准确率与召回率。
| 图表编号 | XD0091817400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 刘倩、李宁、田英爱 |
| 绘制单位 | 北京信息科技大学计算机学院、北京信息科技大学计算机学院、北京信息科技大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}