《表1 文档集统计信息:基于集成学习的动态Web页面语义标注方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证本文方法的性能,实验选用2个不同的数据集,1个是某网站新闻,另1个是摄影网站。本节通过Java环境下的1个页面解析程序包HTMLParser把Web页面集合中的页面变成DOM Tree形式,利用遍历DOM Tree获取初始图像集和文本集。对图像集进行滤波处理,获取含2800幅图像的图像集。文本包含源于Web页面结构中不同位置的文本,用P1,P2,P3,P4,P5进行描述。转换后统计信息用表1进行描述。
| 图表编号 | XD00103725200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.31 |
| 作者 | 邱金鹏 |
| 绘制单位 | 衡水市人民医院 |
| 更多格式 | 高清、无水印(增值服务) |
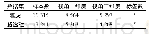



{kind=link}