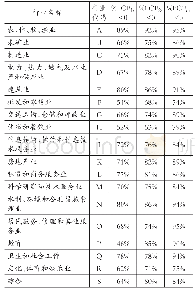
《表1 不同算法的回报对比表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
如表1所示,虽然在实验收敛初期第0步、第60 000步和第255 000步时,Q-Learning算法的回报值分别比MPRL算法的高68、162和37,但在第130 000步和第645 000步,MPRL算法保持稳定收敛,Q-Learning算法的回报值曲线却出现较大波动。从长期来看,基于并行强化学习算法的收敛性和稳定性表现了更好的性能。
| 图表编号 | XD0090176500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 陈建平、康怡怡、胡龄爻、陆悠、吴宏杰、傅启明 |
| 绘制单位 | 苏州科技大学电子与信息工程学院、苏州科技大学江苏省建筑智慧节能重点实验室、苏州科技大学苏州市移动网络技术与应用重点实验室、苏州科技大学电子与信息工程学院、苏州科技大学江苏省建筑智慧节能重点实验室、苏州科技大学苏州市移动网络技术与应用重点实验室、苏州科技大学电子与信息工程学院、苏州科技大学江苏省建筑智慧节能重点实验室、苏州科技大学苏州市移动网络技术与应用重点实验室、苏州科技大学电子与信息工程学院、苏州科技大学江苏省建筑智慧节能重点实验室、苏州科技大学苏州市移动网络技术与应用重点实验室、苏州科技大学电子与信息 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}