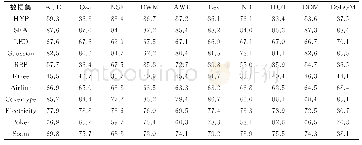
《表1 不同算法的正确分类率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于改进SURF特征与模糊推理的复杂图片中的文字识别》
实验1为了模拟实际情况下复杂图像中文本的倾斜度,测试本文方法的分类精度,选择标准文字数据库中每个汉字的4种字体组成训练集,形成文字类别数据库。如图3所示,训练集中的每个图像每1°顺时针和逆时针旋转以生成测试集。将训练集中的汉字图像分别倾斜1°~3°,得到共6幅汉字图像。表1列出了本文提出的方法及对比方法对测试集的识别率。从表1可以看出,当倾角较大时,网格特征的分类效果降低,HOG特征的识别率变化不大,本文提出的方法对于适度倾斜具有鲁棒性。为了测试各个算法的检测性能,本文以F度量作为评估算法性能的指标[23],这里F度量是精度和召回率的调和平均数,权重α取0.5。如表2所示,本文的算法具有较好的检测性能,且取得了较高的F度量。
| 图表编号 | XD0068490000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 陶筱娇、卢锦 |
| 绘制单位 | 陕西科技大学电气与信息工程学院、陕西科技大学电气与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}