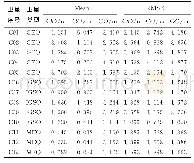
《表1 3种情感语音合成方法的基频 (F0) 和时长 (Dur) 的RMSE Tab.1 RMSE of F0 and duration (Dur) for three emotional speec
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
客观评测通过计算原始语音与合成语音在基频和时长上的均方根误差(root mean square error,RMSE),以及梅尔倒谱失真(Mel-cepstral distortion,MCD)、频带非周期性失真(band a periodicity distortion,BAPD)和V/UV交换误差来评测合成语音的质量,评测结果分别如表1和表2所示。可以看出,在大部分情感中,说话人自适应方法训练的DNN和HMM模型比DNN模型数值更小,有更好的性能。几种情绪浮动较大的情感如愤怒、焦虑的RMSE值在DNN模型上浮动较大,其RMSE值有时会接近或小于基于HMM的说话人自适应训练方法的结果,而轻蔑和中性等弱情感在3种对比实验中的RMSE值比较接近。表1与表2结果表明,本文提出的方法合成的情感语音要优于其他2种方法合成的情感语音。
| 图表编号 | XD006299100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.10.01 |
| 作者 | 智鹏鹏、杨鸿武、宋南 |
| 绘制单位 | 西北师范大学物理与电子工程学院、西北师范大学物理与电子工程学院、西北师范大学物理与电子工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}