《表2 实验结果图:基于k-means聚类的Bagging算法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在Weka实验环境下,其部署的选项如下:将常规Bagging算法的迭代次数设置为10次,将改进算法的迭代次数设置为100次,同时将-k选项设置为(10,100)次(设置集群数量的-k选项)。然后,可以在相同的水平上对这些方法进行评估,因为所有的集合都具有相同的大小,等于10(每个集合由10个单独的分类器组成)。我们选择REPTree作为所有算法的基分类器。此外,将实验类型设置为交叉验证(crossvalidation),折叠次数为10次。为了增强实验的鲁棒性,我们对每个数据集重复测量了10次。实验结果如表2所示。
| 图表编号 | XD0062111100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.10 |
| 作者 | 金朝 |
| 绘制单位 | 武汉第二船舶设计研究所 |
| 更多格式 | 高清、无水印(增值服务) |

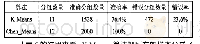




{kind=link}