《表1 实验数据库:基于k-means聚类的Bagging算法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
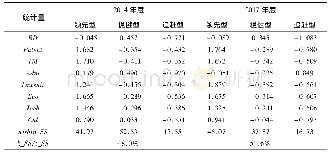
通过实验验证基于聚类的Bagging改进算法性能。为了验证算法在多领域的普适性,实验从UCI机器学习库中选择了10个来自选举、医疗、食品、信用评级等多领域的数据库,其中4个数据库包含遗失数据,其主要特征如表1所示。采用70%训练集锦和30%测试集的比例划分数据集。运行实验的平台是由新西兰怀卡托大学提供的机器学习平台Weka,Weka平台是用于数据挖掘任务的机器学习算法和数据预处理工具的集合。Weka能够处理主要的数据挖掘问题:回归、分类、聚类、属性选择等。通过Java编程,Weka提供了包括准备输入数据、统计评估学习算法、可视化输入数据和学习的测试输出等数据分析的全流程解决方案。
| 图表编号 | XD0062110800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.10 |
| 作者 | 金朝 |
| 绘制单位 | 武汉第二船舶设计研究所 |
| 更多格式 | 高清、无水印(增值服务) |
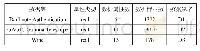




{kind=link}