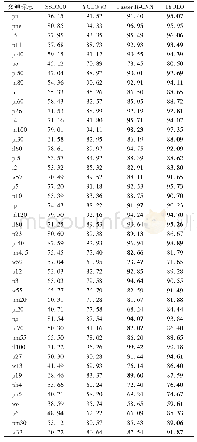
《表2 3种算法奖励值对比表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由表可见,学习率是影响本实验数据的最大因素。较大的学习率容易导致结果不收敛且奖励值偏低,而过小的学习率收敛较好但是程序运行过慢且值不能够达到较高的水平。经过大量调试参数的观察结果可得到结论,学习率为0.01,衰减率0.9,贪婪值0.9时是本实验较好的参数设置。因此接下来本文将3种强化学习算法加入到已经配置好的参数的游戏环境中进行训练,观察其结果。如表2所示。
| 图表编号 | XD0061685500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.20 |
| 作者 | 孙鹏、孙若莹、刘滨翔 |
| 绘制单位 | 北京信息科技大学信息管理学院、北京信息科技大学信息管理学院、北京信息科技大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}