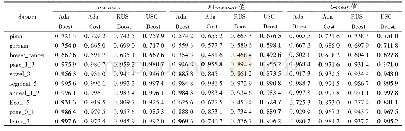
《表1 三种算法的实验F1值结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证本算法的可行性,第一组实验使用三种算法进行对比实验,分别是文中所提出的基于加权语义的方法、文献[12]提出的基于复杂网络特性的方法和文献[1]提出的基于向量空间模型的方法,三种方法分别标记为:N-EMD-1、N-NET-2、N-VSM-3。实验中公式βi采用文献[8]的取值,即β1为0.4、β2为0.3、β3为0.3,特征维数取值为1 200,实验时采用5折交叉验证法,取这五次的F1平均值作为最终的分类结果。三种实验的文本聚类结果在各类别中的F1值和平均值如表1所示。
| 图表编号 | XD0076419300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.28 |
| 作者 | 张弛、张贯虹、周艳玲 |
| 绘制单位 | 合肥学院计算机科学与技术系、合肥学院计算机科学与技术系、合肥学院计算机科学与技术系 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}