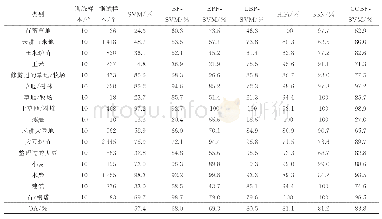
《表2 在Indian Pines数据集上由各种算法得到的最高评价指标及其对应的维数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
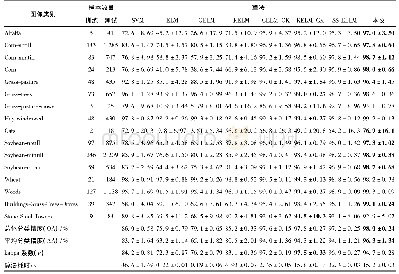
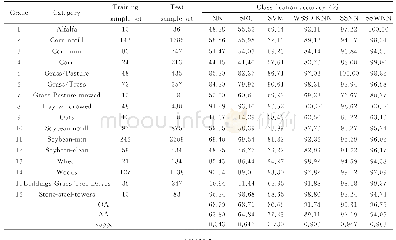
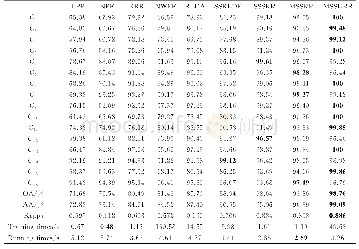
为比较各个算法的性能,实验中,随机选取每类地物样本的10%作为训练样本,当某类样本数小于100时则随机选取该类中的10个样本作为训练样本,其余样本作为测试样本。每种算法重复进行10次求平均值。为对比分析不同算法在不同维数下的分类效果,图7给出了在不同算法下AA,OA和Kappa系数与前100维低维子空间维数的关系。表2给出了不同算法在训练样本数相同的情况下最高分类精度评价指标和所在低维子空间的维数。
| 图表编号 | XD0061498500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 阿茹罕、何芳、王标标 |
| 绘制单位 | 西安培华学院会计与金融学院、火箭军工程大学核工程学院、96862部队 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}