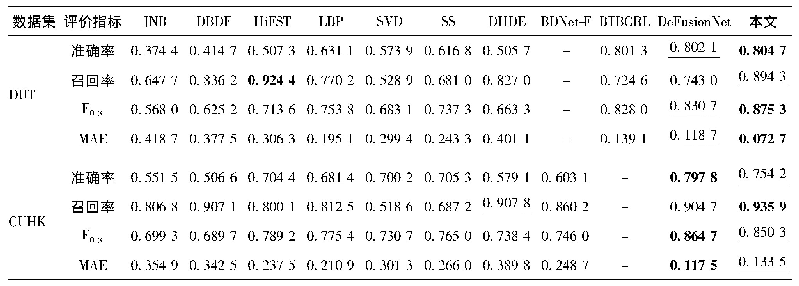
《表2 Con-Text数据集上不同方法结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(注:*表示使用Con-Text子集测试)
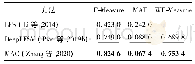
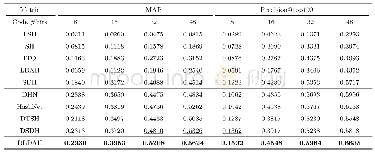
为了验证本文的解决方法,模型整体训练之后在Con-Text数据集上做测试,测试结果见表2。其中带有星号的栏目表示使用Con-Text子集来测试,不带星号的栏目表示使用全部数据集进行训练并测试。在整个数据集24 255张图像当中,对每一类随机抽取10%的图像作为测试图像总共2 426张。包含有文字的子数据集中,共有7 589张训练图像,844张测试图像。从实验结果来看视觉结合文本的方法进一步提升了图像分类的效果,同时相比文献[7]的结果又有4个百分点的提升,从而验证图像文本行检测较图像单词检测更能帮助提升图像细分类。表2纵向上对应的类别分别为:热点、宠物店、电影院、学校、餐车、按摩中心、宾馆、面包店、葬礼、电脑中心、买酒、小卖部、洗衣店、烟草店、修理部、当铺、茶馆、小酒馆、咖啡、酒馆、牛排餐厅、折扣店。
| 图表编号 | XD0059466100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 袁建平、陈晓龙、陈显龙、何恩杰、张加其、高宇豆 |
| 绘制单位 | 北京恒华伟业科技股份有限公司、北京恒华伟业科技股份有限公司、北京恒华伟业科技股份有限公司、北京恒华伟业科技股份有限公司、华北电力大学控制与计算机工程学院、华北电力大学控制与计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}