《表1 模型在SVT数据集上的测试结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
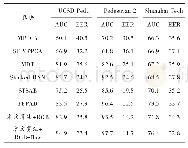
实验主要分为2个部分,首先单独训练文本识别模型,其次再训练整体模型。为了准确判别文本识别模型的能力,将训练之后的模型在SVT数据集上做测试,并与其他文献方法进行对比。本实验认为如果一个文本候选框的IoU比率大于0.5,并且识别出来的文本也匹配,则该结果正确;若识别的文本与实际文本不同,则使用其编辑距离来计算模型的准确率。本文在SVT数据集验证了模型,在测试阶段仅使用了90 k的词典作为参考,并与其他文本识别系统进行比较,用F值(F-measure)来衡量模型的性能,其中F值是结合模型的准确率和召回率的综合指标,以百分比的形式表示,测试结果见表1。
| 图表编号 | XD0059466000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 袁建平、陈晓龙、陈显龙、何恩杰、张加其、高宇豆 |
| 绘制单位 | 北京恒华伟业科技股份有限公司、北京恒华伟业科技股份有限公司、北京恒华伟业科技股份有限公司、北京恒华伟业科技股份有限公司、华北电力大学控制与计算机工程学院、华北电力大学控制与计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}