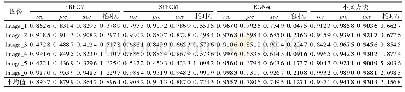
《表2 在STL-10上初始化C1的对比实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
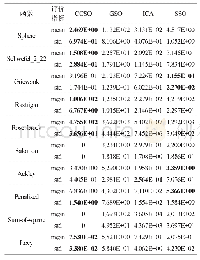
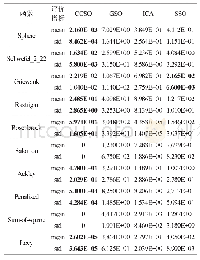
从表2可以看出,当初始化C1时,该方法比3种初始化方法(即Msra、Xavier和Random)有更好的准确率.但是使用不同比例的无标签数据对准确率的提高程度不同.例如,当无标签数据比例超过30%后,准确率并不会随着无标签数据比例的增加而提高,反而出现了下降.从图5中可以看出,当迭代次数超过1 000后,使用30%无标签数据的准确率超过了Msra方法,并达到较高的值,即62.905%;与3种初始化方法相比,它的准确率提高了3%~19%.
| 图表编号 | XD0051748500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.10 |
| 作者 | 欧军、李玉鑑、沈成恺 |
| 绘制单位 | 北京工业大学信息学部、北京工业大学信息学部、桂林电子科技大学人工智能学院、北京工业大学信息学部 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}