《表2 keseq2seq模型训练数据》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
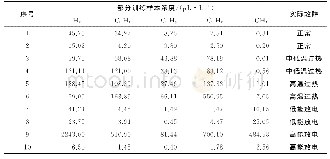
首先对所有古诗进行分词处理;然后计算每个词的TextRank分值,将TextRank分值最高的词作为每句诗的关键词,一首诗中提取出四个关键词,如表1所示。从所有训练集中共提取了289 900个关键词。将每首诗的关键词处理成表2形式用于训练keseq2seq模型;将每首诗的诗句和对应的关键词处理成表3形式用于训练pgseq2seq模型。
| 图表编号 | XD003884800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 黄文明、卫万成、邓珍荣 |
| 绘制单位 | 桂林电子科技大学计算机与信息安全学院、广西高校云计算与复杂系统重点实验室、桂林电子科技大学计算机与信息安全学院、桂林电子科技大学计算机与信息安全学院、广西高校云计算与复杂系统重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
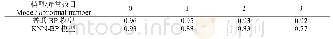


{kind=link}