《表1 短语成分分析模型训练数据集》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对于短语成分分析,本文使用的是CTB5和CTB7数据集,用来训练不同性能的短语成分分析模型。这2个数据集分别来自Penn Chinese Treebank(CTB)版本5(CTB5)[26?27]和版本7(CTB7)[28],在CTB5上,使用标准的数据切分方式[10]。对于CTB7,为了更好地学习和测验预测能力,采用类似CTB5的切分方式。为了显示训练出的2个模型的扩展能力,本文使用了完全相同的测试集。遵照一般标准[10],测试集的分词仍然使用数据集提供的标准分词,词性标注使用stanford词性标注器标注的结果。表1中给出了2个数据集的统计信息。
| 图表编号 | XD00170137100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 刘娜娜、程婧、闵可锐、康昱、王新、周扬帆 |
| 绘制单位 | 复旦大学计算机科学技术学院、上海智能电子与系统研究院、复旦大学计算机科学技术学院、上海智能电子与系统研究院、上海秘塔网络科技有限公司、微软亚洲研究院、复旦大学计算机科学技术学院、上海智能电子与系统研究院、复旦大学计算机科学技术学院、上海智能电子与系统研究院 |
| 更多格式 | 高清、无水印(增值服务) |
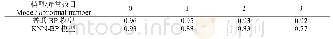



{kind=link}