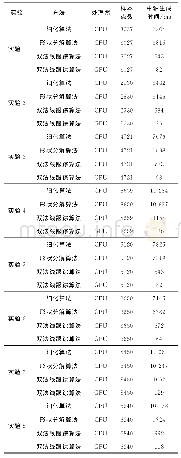
《表1 各类并行算法的比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
关联规则挖掘算法的改进主要是对原始数据集格式、算法使用的数据结构,挖掘过程中产生候选项集的数量以及挖掘过程扫描数据库的次数等方面进行优化。以上各类并行算法之间的比较见表1,结合上一节中对各类并行算法的时间复杂度和空间复杂度的分析,在并行Apriori算法中,除R-Apriori算法在挖掘过程不产生候选集,其他算法均会产生候选集,且R-Apriori算法的时间复杂度和空间复杂度也优于其他并行Apriori算法,由此可以得到减少生成候选集的数量一定程度上可以提高关联规则挖掘算法效率。SIAP算法和HFIM算法使用了水平和垂直两种数据格式,在生成频繁1项集的阶段减少了算法的时间复杂度和空间复杂度,由于在生成关联规则的时候没有减少生成候选项集的数量,因此算法整体复杂度比R-Apriori算法高,但比YAFIM算法要低。在使用的数据结构方面,R-Apriori算法使用的是布隆过滤器,SIAP、FISM、AMRDD、Spark+IApriori、SP-Apriori、DPBM等算法使用的是矩阵,YAFIM使用的是哈希树,HFIM使用的原始数据结构,同等情况下,使用了特殊数据结构的算法在生成频繁k项集阶段比没有使用特殊数据结构的算法在时间和空间复杂度上均有明显优势,在使用了特殊数据结构的算法中,R-Apriori算法使用的布隆过滤器比其他算法使用的布尔矩阵更有优势,是因为布隆过滤器可以表示全集,而其他任何数据结构都不能,所以在时间和空间方面更具有优势。使用特殊数据结构的算法在扫描数据库次数方面都少于k次,甚至只需扫描一次数据库,明显减少了内存占用和扫描数据库的时间。在并行FP-Growth算法中,由于FP-Growth算法本身只需扫描数据库两次,因此算法效率均比Apriori算法好。IPFP-growth和CWBPFP算法不产生候选集,在迭代计算时优于其他同类算法,SMFI和RPFP算法使用了特殊数据结构,使算法在迭代的挖掘频繁模式阶段具有更高的效率。FP-VFIM算法是唯一使用了垂直数据格式的算法,在查找频繁项集过程比同类算法更具有优势。
| 图表编号 | XD0035467400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 刘莉萍、章新友、牛晓录、郭永坤、丁亮 |
| 绘制单位 | 江西中医药大学计算机学院、江西中医药大学计算机学院、江西中医药大学药学院、江西中医药大学计算机学院、江西中医药大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}