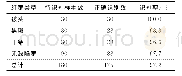
《表4 基于SVM的声效识别结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
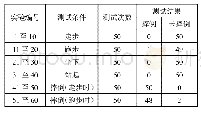
表5所示为利用式(11)定义的模型融合方法来识别声效模式的结果.其中,整体谱特征用于构建GMM模型,MFCC用于训练MLP,SIE用于训练SVM.当权重系数α的值位于区间[0.15,0.3],β的值位于区间[0.2,0.4]时识别效果最优.可以看出,当利用模型融合的方式来利用3种特征识别声效时,其精度要高于表2~表4中单独使用1种特征时的精度.
| 图表编号 | XD003465700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.04.01 |
| 作者 | 晁浩、鲁保云、刘永利、刘志中、宋成 |
| 绘制单位 | 河南理工大学计算机科学与技术学院、河南理工大学计算机科学与技术学院、河南理工大学计算机科学与技术学院、河南理工大学计算机科学与技术学院、河南理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}