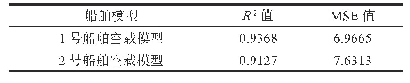
《表5 基于Na觙ve Bayes机器算法的回归结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:括号内为t值;***、**和*分别表示1%、5%和10%的显著性水平。
本文采用了关键词抓取法来度量文本信息语调,例如“增加”等正面词;“减少”等负面词。然而这些词在具体的语境中可能发生语义反转,例如费用的增加与费用的减少、损失增加与损失减少等等情况。这种关键词抓取法在语句情绪倾向的度量中可能存在误差,可能会影响结果的可靠性。对此,本文采用Li(2010)的Na觙ve Bayes算法,[5]对语句结构进行分析。具体方法是预先设置如“收XXX增”“收XXX提”“费XXX增”和“费XXX提”等基本语句结构元。这样可以忽略语句中其他成分的干扰,仅提取基本成分的名词与形容词,可以更准确地分析语句情绪倾向。本文预先设置的语句数达到264个,能够基本准确地模拟人工阅读的判断标准,所得结果基本可靠。根据Na觙ve Bayes算法得到的文本信息,对模型(3)进行回归,结果见表5(表5在原变量名前分别加Bayes表示Na觙ve Bayes算法下的变量代码)。由表5的回归结果可知,在采用机器学习方法度量文本信息语调后,本文结论并未发生改变。
| 图表编号 | XD0029719800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.15 |
| 作者 | 许文瀚、朱朝晖 |
| 绘制单位 | 浙江大学宁波理工学院商学院、浙江大学宁波理工学院商学院、浙江工商大学财务与会计学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}