《表9 PSM匹配样本和DID模型回归结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《上市公司信息披露的文字主观叙述与盈余操纵——基于机器学习法提取主观模式的研究》
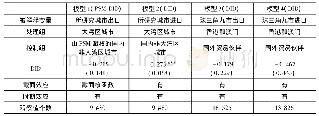
在前文的回归检验中,采用了整体混合样本进行检验,本文在稳健性检验中进一步采用倾向性评分匹配方法进行1:1匹配,为发生过财务重述的上市公司在没有发生过财务重述的上市公司中寻找配对样本,以配对后得到的实验组和控制组的样本重新对回归模型(I)和回归模型(II)进行回归。首先将进行过财务重述的上市公司的公司年标记为实验组(treat=1),没有发生过财务重述的上市公司的公司年标记为控制组(treat=0);选取的匹配变量为:行业(Industry)、上市年份(Age)、公司规模(Size)、资产负债率(Lev)、总资产报酬率(ROA)和营业总收入增长率(Growth),然后进行Logit回归;根据倾向性评分对每一个财务重述前的样本进行最近邻一对一匹配,最终得到632组(1264个)配对样本。表9中的第2列和第3列报告了PSM匹配样本的回归结果,财务重述前(Restate_pre)的回归系数仍然显著为正,利用PSM方法得到匹配样本进行的稳健性检验得到的回归结果与前文的回归结果是一致的,仍然支持本文提出的假设1和假设2,上市公司会在年报中采用更主观的叙述配合盈余操纵行为。
| 图表编号 | XD0028551700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.10 |
| 作者 | 毛怡欣 |
| 绘制单位 | 厦门大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}