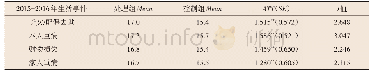
《表4 倾向值匹配的平行检定结果 (N=1652)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《制度压力下的企业研发投入与社会责任——基于中国私营企业调查数据的实证研究》
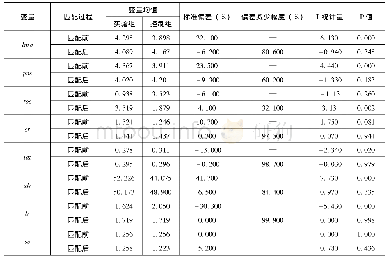
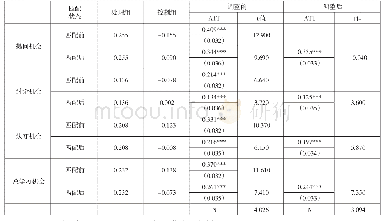
图2是处理组(有研发投入企业)与对照组(无研发投入企业)的倾向值密度函数图。从图中可以看到,对照组的企业进行研发投入的概率集中在0.2,而处理组企业的倾向值峰值则出现在0.7。另外,从图中可以直观看出,两条密度函数曲线交叉的部分较多,因此可以认为倾向值匹配的共同支撑假设(Common Support Assumption)较容易得到满足。本研究同时采用三种不同的匹配方法进行样本匹配及估计处理效应,包括最近邻匹配法、半径匹配法和核匹配法。采用三种匹配方法,处理组和对照组样本均落在“On support”(受支撑)区域内,结合密度函数图可认为共同支撑假设得到满足。接着,对核匹配法的结果进行平行假设(Balancing Assumption)检验,表4呈现了检验的结果(最近邻匹配和半径匹配的结果类似,不再重复)。通过匹配,大部分变量都消除了组间差异。除了管理者经历以及是否属于中部企业两个变量在匹配后仍然存在明显的组间差异外,其余变量匹配后的差异都变得不显著了。绝大部分变量的标准误偏差绝对值在匹配后都控制在了0.1以内。伪R2从匹配前的0.194下降到匹配后的0.008,可见本研究的匹配变量选择与匹配方法实现了大部分匹配变量在处理组和对照组之间的平衡性,平行假设得到满足,倾向值匹配估计是有效的。
| 图表编号 | XD0024638300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.01.01 |
| 作者 | 谢昕琰、楼晓玲 |
| 绘制单位 | 广东财经大学应用社会学系、杭州电子科技大学工商管理系 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}