《表3 IMDB数据集上测试精度比较》
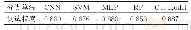 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验使用CNN[11]作为基学习器,并且使用预训练好的google word2vec的参数(300维)初始化词向量。在粒度划分阶段使用静态方式选定基学习器的数量,规定最大的基学习器数量为N (N=1+2+3+4=10),使用10个基学习器构造出最后的集成学习器。实验部分将本文提出的算法与SVM (Support vector machine),CNN,MLP(Multilayer perceptron)和RF (Random forest)[12]进行了对比分析,算法在测试集上的分类精度如表3所示,10个基学习器在测试集上的性能如图3所示。
| 图表编号 | XD00224182900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.01 |
| 作者 | 王子一、徐苏平、商琳 |
| 绘制单位 | 计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系、计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系、计算机软件新技术国家重点实验室(南京大学)、南京大学计算机科学与技术系 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}