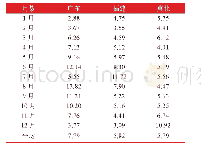
《表1 电力预测误差的百分比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
根据某地区电力相关信息情况,建立经济信息资料库、地区往年使用电力的消费信息资料库、政府相关政策的数据信息资料库和用电客户详细信息资料库等图表。在信息资料库建设过程中将相关的身份资料删除,选择其中1 446 000个用户作为用电判断的样本进行模拟分析。根据这些样本将这座城市以区域划分不同的类型:工厂区域、购物区和住宅区,住宅区存在使用电力量大、使用电力人数多和电力信息复杂等特点,该文以居民日常和工作用电量作为研究凭证,根据企业有效资料对用户情况加以分析;同时根据居民缴纳的电费金额和实际的电力花费把使用电力客户分为以下4类:1)常生活使用电量(A类)。2)工厂工作使用电量(B类)。3)乡村种植使用电量(C类)。4)贸易活动使用电量(D类)。用电客户详细分类的成果如下,A类客户的用户数量为27863,企业数量为289。B类客户的用户数量为111 764,企业数量为791。C类客户用电数量为193 670,企业数量为1 650,D类客户的数量为1 112 750,企业数量为7 706。为了使文章提出的聚类计算方法更加真实可靠,工作人员将传统算法与聚类计算方法的相关性能进行对比,对比结果如下:1)算法中类内的距离平均值传统算法为0.5754,聚类计算方法为0.5452。2)类内具体的系数传统算法为0.6362,聚类计算方法为0.8164。3)类中心的相对平均数值传统算法是1.3059,聚类计算方法为1.2516。4)类中心实际系数传统算法为0.3919,聚类计算方法为0.3017。具体电力预测误差见表1,从这些数据可以看出,该文提出的相关方法在距离这种属性中表现并不突出,但是从增加样本的相关上看成果显著[4]。
| 图表编号 | XD00213464100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.10 |
| 作者 | 刘洋 |
| 绘制单位 | 内蒙古电力(集团)有限责任公司内蒙古电力经济技术研究院分公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}