《表1 实验数据集统计:融合重叠社区正则化及隐式反馈的协同过滤方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
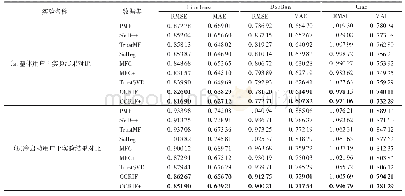
本文选取了Film Trust、Dou Ban以及Ciao三个数据集进行实验。这些数据集是在社交网站上运行爬虫程序获取的。具体的:Film Trust数据集(http://www.librec.net/datasets.html)是在电影推荐网站Film Trust(www.trust.mindswap.org/)爬取获得,用户可以根据自己的偏好对电影进行评级,同时用户之间可以建立信任关系;Dou Ban数据集(https://www.cse.cuhk.edu.hk/irwin.king.new/pub/data/douban)是在社交网站Dou Ban(www.douban.com)上抓取获得的,包含了用户对于书籍、音乐、电影的评分信息,同样该社交网站也允许用户添加信任朋友;Ciao数据集(http://www.jiliang.xyz/trust.html)是在商品评价网站Ciao(www.ciao.co.uk)上抓取的,允许用户对商品进行评价。不同数据集的评分范围不尽相同,Film Trust评分范围为0.5~4,步长为0.5;Douban以及Ciao评分范围为1~5,步长为1。数据集统计特征如表1所示,表中#user(n)表示数据集中的用户数,#item(m)表示数据集中的商品数,#ratings表示数据集中的评分数,relation表示社交矩阵中用户之间的关系数,RDensity表示评分矩阵中数据的稀疏程度,SDensity表示在社交关系矩阵中数据的稀疏程度,nˉ代表单个商品的平均评分用户数,mˉ代表单个用户的平均评分商品数,sˉ代表单个用户的平均关系数。
| 图表编号 | XD00201763500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.10 |
| 作者 | 李翔锟、贾彩燕 |
| 绘制单位 | 北京交通大学计算机与信息技术学院、交通数据分析与挖掘北京市重点实验室(北京交通大学)、北京交通大学计算机与信息技术学院、交通数据分析与挖掘北京市重点实验室(北京交通大学) |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}