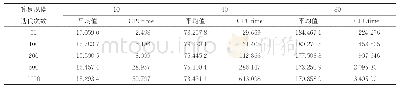
《表4 求解迭代总次数比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
图8为两种算法每平均100回合中所取得平均累积奖励曲线对比,累积奖励越高,代表机器人按照期待的目标选出来更优的动作。从图上看来,两条曲线都呈递增趋势,且当训练回合超过某一定值后,均趋于稳定。但是比较表4数据,DDPG算法用了4 323回合到达最大累积奖励,而改进后的DDPG算法迭代2 037次即到达最大累积奖励,比前者提升了45.7%。可见,RBF改进后的DDPG算法具有更高的效率。
| 图表编号 | XD00201635400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.15 |
| 作者 | 周友行、赵晗妘、刘汉江、李昱泽、肖雨琴 |
| 绘制单位 | 湘潭大学机械工程学院、湘潭大学机械工程学院、湘潭大学机械工程学院、湘潭大学机械工程学院、湘潭大学机械工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}