《表1 污染指标与变量:预训练语言模型BERT在下游任务中的应用》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
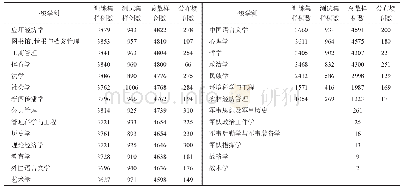
选取4个数据集Reuters[10]、AAPD、IMDB reviews和Yelp 2014 reviews进行评测。Reuters和AAPD是多标签文档,IMDB和Yelp2014只包含单一标签。数据集中随机选取80%作为训练语料,10%作为测试语料,10%作为验证集。表1列出了4个数据集的规模,其中C表示分类任务的类别数,N表示语料包含的文档数,W和S分别表示每篇文档包含的平均单词数量和平均句子数量。
| 图表编号 | XD00183558100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.01 |
| 作者 | 段瑞雪、巢文宇、张仰森 |
| 绘制单位 | 北京信息科技大学计算机学院、国家经济安全预警工程北京实验室、北京信息科技大学计算机学院、北京信息科技大学信息管理学院、国家经济安全预警工程北京实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}