《表1 预训练语言模型对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
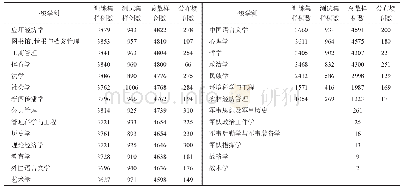
常见的预训练语言模型结构如图2所示[11],有编码输入层、网络结构层、编码输出层。预训练语言模型的区别主要体现在网络结构层以及预训练时对语言建模的任务。如ELMO使用双向LSTM结构,BERT、GPT使用Transformer[20]结构。与LSTM相比,Transformer中引入self-attention结构与多头注意力机制,可以捕获更多的文本信息,同时Transformer可以做到并行化计算以及设计更深的神经网络。本文将近年来出现的预训练语言模型根据建模方式、模型结构、模型介绍等进行整理,如表1所示。
| 图表编号 | XD00163010400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 张超然、裘杭萍、孙毅、王中伟 |
| 绘制单位 | 陆军工程大学指挥控制工程学院、陆军工程大学指挥控制工程学院、陆军工程大学指挥控制工程学院、陆军工程大学指挥控制工程学院、中国人民解放军73658部队 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}