《表2 标注样例:基于预训练BERT字嵌入模型的领域实体识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
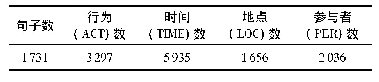
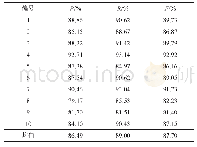
本文模型的预训练语料使用了2000份中文医学文献,训练语料来自中国健康信息处理学术会议(CHIP2018)评测一:中文电子病历中临床医疗实体及属性抽取任务中发布的600份电子病历训练数据。首先对文本进行必要的预处理(去除特殊字符、英文大小写以及部分标点符号等),并在处理好的文本中加入了噪音。按照5:1的比例对原始语料中肿瘤原发部位以及转移部位进行人工标注,采用BIO形式的序列标注法,B表示实体的开始,I表示实体的延续,O表示非实体部分。数据样例如表2所示。
| 图表编号 | XD00137032100 严禁用于非法目的 |
|---|---|
| 绘制时间 | |
| 作者 | 丁龙、文雯、林强 |
| 绘制单位 | 南华大学计算机学院、南华大学计算机学院、南华大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}