《表3 各手写体汉字识别方法的比较》
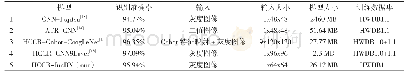 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表3展示了基于ICDAR2013数据集的不同识别方法的比较。可以看出,与表中的方法1、2相比,HCCR-IncBN模型在识别准确率和模型参数的数量方面都具有较大的优势。方法1是2013年ICDAR手写体识别比赛的冠军,其输入表示很小,但是模型存储量高达2460MB。随着算法的改进和网络的优化,近几年一些成功的模型涉及的计算参数数量逐步降低。方法2是ATR-CNN的单一模型,其输入是1x48x48的二值化图像,但是模型存储量约是我们的两倍。方法3也是基于GoogLeNet,在识别准确率方面HCCR-IncBN比其低了0.41%,但是在模型存储方面我们更优一些,具体来说,HCCR-Gabor-GoogLeNet使用的是Inception-v1模块且提取了原图像的Gabor特征,其输入表示大小为9x120x120,而HCCR-Inc BN模型是基于Inception-v2模块,输入表示大小为1x64x64,且训练集只使用了HWDB1.1。方法4致力于设计一个紧凑型的CNN网络来提高手写体识别的效率,在模型存储方面具有很大的优越性,与之相比,HCCR-IncBN模型的输入表示较小,且方法4的模型在训练过程中要不断的进行卷积层的低秩分解和修剪权重的操作,模型训练期间会耗费大量的时间和计算资源。
| 图表编号 | XD00173394800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.10 |
| 作者 | 侯杰、倪建成 |
| 绘制单位 | 曲阜师范大学软件学院、曲阜师范大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}