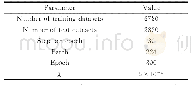
《表8 手写数字识别数据集预处理裁剪率比较结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
最后,为验证本文所提的RBKNN算法对类不平衡问题的优化效果,使用斯坦福大学提供的手写数字识别数据集对算法进行了进一步测试。该数据集共有5 000个样本,10个类别,每个类别500个样本。将数据集随机均分成三份,一份作为训练集,一份作为测试集,并取最后一份中全部偶数类别样本作为补充训练集添加到训练集中。这样得到的训练集中的偶数类别样本数便是奇数类别样本数的两倍,以形成类不平衡的效果。本实验比较了本文提出的RBKNN算法和已有的DBKNN算法[16]。实验中所有参数与上一组实验一致,实验结果经过5次重复测试求平均值,具体比较结果如表7和表8所示。
| 图表编号 | XD00107089900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.15 |
| 作者 | 王子旗、何锦雯、蒋良孝 |
| 绘制单位 | 中国地质大学(武汉)计算机学院、中国地质大学(武汉)计算机学院、中国地质大学(武汉)计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}