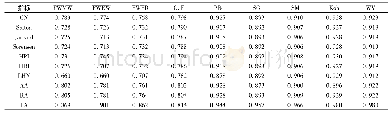
《表1 AI CHALLENGER数据集上各模型的指标》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文一共采用了7种指标衡量中文描述生成结果的质量.BLEU[15]:常用来当作机器翻译的评价指标,能够分析机器生成语句和参考语句间的N元文法准确率.METEOR:利用单精度的加权调和平均数和单字召回率的方法改善BLEU指标存在的问题.ROUGE-L:通过比较召回率的相似度来度量指标,不足之处是该算法的N元文法要求是连续的.CIDEr:通过共识评价指标,是一种特别的图像描述评价指标,具有重要参考价值.在表1中,用B@1,2,3,4指代BLEU-1,2,3,4,Rouge指代ROUGE-L,Incepv4指代Inception-v4,Incepresv2指代Inception-ResNet-v2,ATT指代注意力机制,MA指代记忆助手.
| 图表编号 | XD00172669000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 郭淑涛、赵德新 |
| 绘制单位 | 天津理工大学计算机科学与工程学院、天津理工大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}