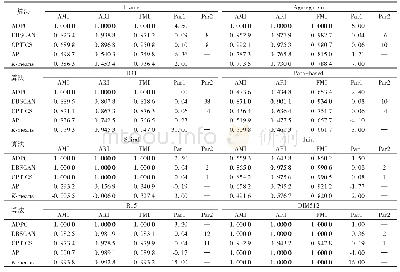
《表4 人工数据集上各聚类算法的评价指标值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了进一步验证算法的性能,将自适应DPC算法与DBSCAN、OPTICS、AP、K-means等几种常用的聚类算法进行对比,聚类结果如表4所示,DPC、DBSCAN、OPTICS、AP、K-means在各数据集的评价指标值来源文献[5]。表中Par1、Par2代表各算法的参数,表中“—”表示没有对应值,即Par2列出现“—”表示该算法只有一个参数。表4中算法的参数说明:ADPC算法有一个参数截断距离(浮点数),表示各样本点平均邻居数约占数据集样本点总数的Par1%;DBSCAN和OPTICS算法,它们都有两个参数:邻域半径ε(浮点数)和minpts(邻域最少点数,即半径内的期望样本个数,整数);AP算法有一个参数偏好参数Preference(浮点数),表示样本点作为聚类中心的参考度;K-means算法有一个参数K(整数),表示设定K个聚类中心。自适应DPC算法在数据集Flame、Aggregation、R15、D31、Path-based、Spiral、DIM512、DIM1024均比其他算法表现更好。自适应DPC算法是对标准DPC算法上的改进,它继承了DPC算法的优势,同时自适应DPC算法已将截断距离参数调至最优,避免了标准DPC算法中的参数设置的影响,这些因素使得改进后的算法效果更佳。DBCSAN算法更适用于非凸样本集聚类,它在聚类的同时还可以找出异常点,因此DBSCAN算法在Jain和Path-based数据集上的表现明显优于其他算法。图5显示了部分数据集的自适应DPC算法聚类结果,同样表明自适应DPC算法良好的聚类效果。
| 图表编号 | XD00163189400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.10 |
| 作者 | 吴斌、卢红丽、江惠君 |
| 绘制单位 | 南京工业大学工业工程系、南京工业大学工业工程系、南京工业大学工业工程系 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}