《表6 帕维亚大学数据集上各算法的总正确率(OA)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由于Mish激活函数更为平滑且对负值轻微允许,嵌入模型使用Mish函数理论上能够允许更好的梯度流,得到更好的准确性和泛化性,从而提升分类效果.此外,反转批量归一化和激活的顺序,变为先激活再批量归一化会使得整个训练过程更加稳定,特别是在前30个训练批次中能够获得更好的泛化性能,也可以提高在测试数据集上的分类效果.印第安松数据集以及萨利纳斯数据集中,不同的地物具有较为相似的光谱曲线,使用单一且固定的距离度量方式不再满足要求,使用关系网络对度量方式进行建模能够更为灵活地得到嵌入与各类原型之间的距离,从而提升分类性能.
| 图表编号 | XD00172560000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 张婧、袁细国 |
| 绘制单位 | 西安电子科技大学计算机科学与技术学院、西安电子科技大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




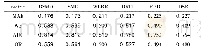

{kind=link}