《表5 印第安松数据集上各算法的总正确率(OA)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
测试数据集中,每类随机抽取的标记样本数目也会影响分类性能,分类总正确率(OA)随着标记样本数目的增加而增加.每类随机抽取的标记样本数目为5、10、15、20、25时,四种算法在测试数据集上分类结果如表5-表7.与Liu等[28]提出的DFSL算法且分类器分别选用最近邻分类器和支持向量机时相比,更换激活函数为Mish函数以及调换归一化和激活顺序后的改进算法在印第安松数据集上取得了更好的表现,而使用关系网络进行关系度量的算法则在萨利纳斯数据集上具有较理想的分类结果.
| 图表编号 | XD00172559700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 张婧、袁细国 |
| 绘制单位 | 西安电子科技大学计算机科学与技术学院、西安电子科技大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



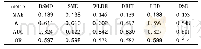


{kind=link}