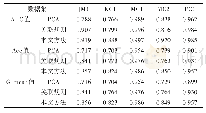
《表4 不同特征属性提取方法在随机森林分类算法上的结果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文经过多次实验得出,在样本差异较大的数据集上先进行特征属性选取,再对数据集作平衡处理,能保留更多特征属性信息,而且在样本数较少的情况下无法发挥特征属性选择方法的优势,故本文设定算法的两个变量minBalance=10,minNum=300。实验主要分为4个步骤:(1)采用SMOTE方法对数据进行过采样,使数据集达到平衡;(2)使用本文提出的特征属性选择方法找到预测能力最好的特征属性集合,表3列出了使用本文方法选择的特征属性集合;(3)使用随机森林分类算法作为基分类算法,验证选择特征属性的预测效果;(4)在步骤(1)的基础上,基于WEKA平台实现基于关联规则方法和PCA方法的特征属性选择,然后使用随机森林分类算法和J48决策树算法对生成的特征属性子集进行分类预测,并与本文方法预测结果进行比较。其中表4列出了使用随机森林算法对上述3种特征属性选择方法选择的特征属性子集进行分类预测的结果比较情况,图1则以直方图形式更直观地展示了使用J48决策树算法对上述3种方法选择的特征属性子集进行分类预测的对比情况。
| 图表编号 | XD00168911300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.15 |
| 作者 | 张洋 |
| 绘制单位 | 湖南省农村信用社联合社信息科技部 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}