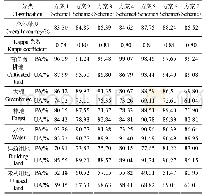
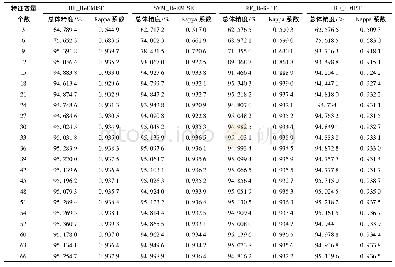
《表6 分类结果精度统计:基于特征优选随机森林算法的农耕区土地利用分类》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:PA,生产者精度;UA,用户精度。
本研究采用总体精度、Kappa系数、生产者精度和用户精度作为农耕区土地利用类型分类结果评价指标,对7种试验方案的分类结果进行对比,分类精度如表6所示。从结果可以看出:方案1的总体精度最低,为83.30%;方案2、方案3和方案4的总体精度有所改善,分别提高1.59%、2.09%和1.32%,Kappa系数则分别提高0.02、0.03和0.02,表明加入植被指数、纹理特征等信息可以有效提升分类精度;方案5将所有特征进行整合进行分类,其总体精度和Kappa系数进一步提高,而采用特征优选的分类方案6精度达到最高,总体精度为88.24%,Kappa系数为0.84,在相同的变量条件下采用SVM方法的总体精度和Kappa系数均低于RF算法。对于单个类别的用户精度和生产者精度而言,再次证明植被指数和纹理特征信息有利于提高分类精度,其中纹理特征对建筑用地精度影响显著,纹理特征信息更适用于纹理信息比较明显的类型。通过对比方案6和方案7可知,基于RF算法的大棚、林地的生产者精度分别提高16.74%和18.5%,而有作物耕地、大棚、林地、水体和未利用地的用户精度分别提高5.32%、11.57%、6.58%、0.54%和9.03%。尽管不同方法在单个土地利用类型分类精度存在差异,总体来说,本研究提出的特征优选方法可以有效改善农耕区土地利用分类的精度,采用方案6最优分类结果如图3所示。
| 图表编号 | XD00135755500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 王李娟、孔钰如、杨小冬、徐艺、梁亮、王树果 |
| 绘制单位 | 江苏师范大学地理测绘与城乡规划学院、江苏师范大学地理测绘与城乡规划学院、国家农业信息化工程技术研究中心、江苏师范大学地理测绘与城乡规划学院、江苏师范大学地理测绘与城乡规划学院、江苏师范大学地理测绘与城乡规划学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}