《表5 模型准确率:基于SVM事故分类的连环追尾事故影响因素分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(%)
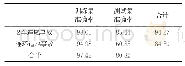
训练SVM模型,并输入测试集进行模型测试,得到了支持向量机模型分类的结果见表5,通过2种事故的准确率对比可以发现,2车追尾事故的分类准确率高于连环追尾事故,这可能与2种事故数据量差距悬殊有关,2车追尾事故数(30 660起)约是连环追尾事故数(7 877起)的4倍,对模型的训练和测试能起到更好的效果。也可能是因为连环追尾事故涉及车辆数不一,从3辆到十几辆均有涵盖,数据统一性较差,特征相对不明显,对模型的训练效果相对不好。但模型总体识别精度(准确度)较高:训练集97.42%,测试集80.32%。这表明连环追尾事故和2车追尾事故之间存在显著差别,而且通过这14个特征变量能够较好的将2种事故区分开来,也就说明选取的特征参数是影响2种事故产生差别的原因。
| 图表编号 | XD00163421200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.28 |
| 作者 | 柳本民、闫寒 |
| 绘制单位 | 同济大学道路与交通工程教育部重点实验室、同济大学道路与交通工程教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}