《表3 特定数据集下的代表数、子序列数及占用空间》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在本节中测试本系统在不同相似性阈值下预处理的时间消耗和空间占用情况。图3显示了在改变相似性阈值ST的情况下,本文系统离线构建查询空间相似组的时间。由图3可知,对于数值比较低的相似性阈值,其构建时间更长,因为要创建的分组更多;随着相似性阈值的增加,构建时间逐渐变小;当阈值增加到一定程度时,构建的时间将保持不变,也就是说,当阈值增加到一定值时,该长度下的所有子序列都已合并。在不同相似性阈值下所形成的代表数量可以显示系统在预处理时生成信息的大小。如图4所示,相似性阈值越大,代表空间中存储的代表数越少。表3显示了在阈值为0.2的情况下各种数据集中代表的个数、切分子序列的个数以及空间占用大小。
| 图表编号 | XD00163344000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 范纯龙、王靖云、滕一平、丁国辉 |
| 绘制单位 | 沈阳航空航天大学计算机学院辽宁省大规模分布式系统实验室、沈阳航空航天大学计算机学院辽宁省大规模分布式系统实验室、沈阳航空航天大学计算机学院辽宁省大规模分布式系统实验室、沈阳航空航天大学计算机学院辽宁省大规模分布式系统实验室 |
| 更多格式 | 高清、无水印(增值服务) |
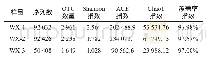





{kind=link}