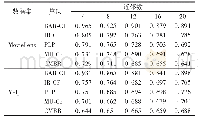
《表3 两个数据集下不同近邻数的调节因子表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从表中可以看出,两个数据集下不同调节因子的MAE值变化趋势基本一致。当近邻数目少于10的时候,调节因子越小,混合算法的准确度也就越高,因为,当近邻数目比较少的时候,也就意味着参与运算的评分数据越少,此时结合时间加权部分可以参考的有效评分很少,导致算法准确度不高。因此,此时可以赋予结合LDA聚类的算法更大的权重,这是由于它不依赖于近邻的数目,有利于提高算法的准确度。而随着近邻数目的增加,结合时间加权的预测评分的准确度会越来越高,更高的权重才会更有利于混合推荐算法的准确度的提高。因此,两个数据集下不同近邻数目的调节因子完全相同,如表3。
| 图表编号 | XD0067428800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 程磊、高茂庭 |
| 绘制单位 | 上海海事大学信息工程学院、上海海事大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}