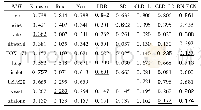
《表3 不同数据集下各算法的NMI》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
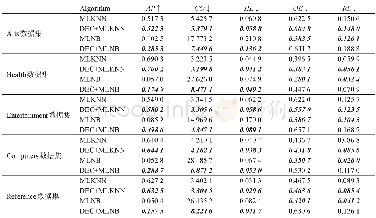
从表3中可以看出,本文算法除了在数据集breast上不是最好,在其他数据集上均好于对比算法。同样以cars数据集为例,本文算法与对比算法相比较在NMI上的提升为14.04%、8.07%、7.51%、13.27%、12.54%、11.01%,平均提升为11.07%。这表明本文所使用的SC-LPCA算法得到的关系矩阵更好地反映了数据样本之间的关系,因此它在标准互信息的值上比其他对比算法更高。同样对cars数据集而言,以在NMI上表现最好的算法LSR为例。它通过约束提高了关系矩阵的内聚性,使得和其他对比算法相比较,它的NMI值会更高。但它仍然是从全局出发来考虑数据集的特性,并没有考虑数据其他同样重要的特征,比如数据集所含的交叉点分布的情况。本文算法通过对中心点的挑选配合LPCA处理以及最后按距离对剩余样本的划分,不仅考虑了样本的局部特征,而且使数据集中的交叉点得到了较好的划分,因此本文算法会在NMI上比其他对比算法更好。
| 图表编号 | XD00107232600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 童涛、文国秋、谭马龙、吴林、杜婷婷 |
| 绘制单位 | 广西师范大学广西多源信息挖掘与安全重点实验室、广西师范大学广西多源信息挖掘与安全重点实验室、广西师范大学广西多源信息挖掘与安全重点实验室、广西师范大学广西多源信息挖掘与安全重点实验室、广西师范大学广西多源信息挖掘与安全重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}